
In a large company, there are a lot of businesses online so the centralized data team cannot catch up with the changes in the business. The ‘centralized` term which means to the operation model where all the tasks related to data are passed to one team. Nowadays, data analysts who have knowledge of common technology such as SQL, python, excel, resolve the business intelligent tasks much faster are distributed across department. The transformation of operation model also needs requirements in data technology also which the data platform team need to provide solutions to share the data service to business teams. In this post, i will share our solution to deliver Airflow - an orchestrator tool as service in our company.
Note: This post only shows up the architecture, our story and features we had added. It’s not a tutorial that describes the implementation in detail!
Airflow introduction:
Airflow has become a major orchestrator tool in the data stack. If you not familiar with ‘orchestrator’ term, it works like cron - a Linux tool which allows you to schedule your application, but with Airflow, we can do more than that and much more related to data tasks. No matter which role you are working on, data engineer, data analyst, data scientist, there are always two kinds of tasks: the ad-hoc and scheduled. You often start with some ad-hoc tasks to find out the best solution to deliver then implement and deploy/schedule them to run somewhere. Moreover, your tasks are not independent but related to each other, so we often don’t define a single task but a pipeline or a complex workflow for tasks. Airflow is the tool which helps you define the task flow then schedule them to run.
Look at the data stack market, there are various tools that allow you to define and schedule tasks like Airflow, for some instances: Prefect, Dagster, Nifi and of course the crontab if you want a simple interface. There is not the best choice for every company or every team so i will not try to compare them in this post but there are several reasons that we chose Airflow are:
- Open-source project: We love open source.
- Majority: Airflow has been proven in a lot of companies and our team members are familiar too.
- Flexible: Look at Airflow architecture, we know that it’s simple one and we can customize it ourselves.
- Can be delivered as a service: To be simple, It can share to user across the team while keeping the management and security.
As default, Airflow by itself can be plug and play which allows user in different team can share together but there are some issues:
- Secret management: Manage all credentials in one Airflow UI that users can see and edit other secrets which is not a clever way.
- DAG management: Airflow does not distinguish the tasks because they are all in the same place called Dag bag. This management approach also has the same disadvantage as the above, users can see and edit other team’s dags.
- Tracing and monitoring: Your airflow server can have thousands of tasks running per day and thousands of deprecated/orphaned tasks need to cover also but there is not easy to manage them.
Because it’s an open-source project for community, so the available features also include some minor bugs which require improvement ourselves.
Our Airflow service architecture:
In user view:
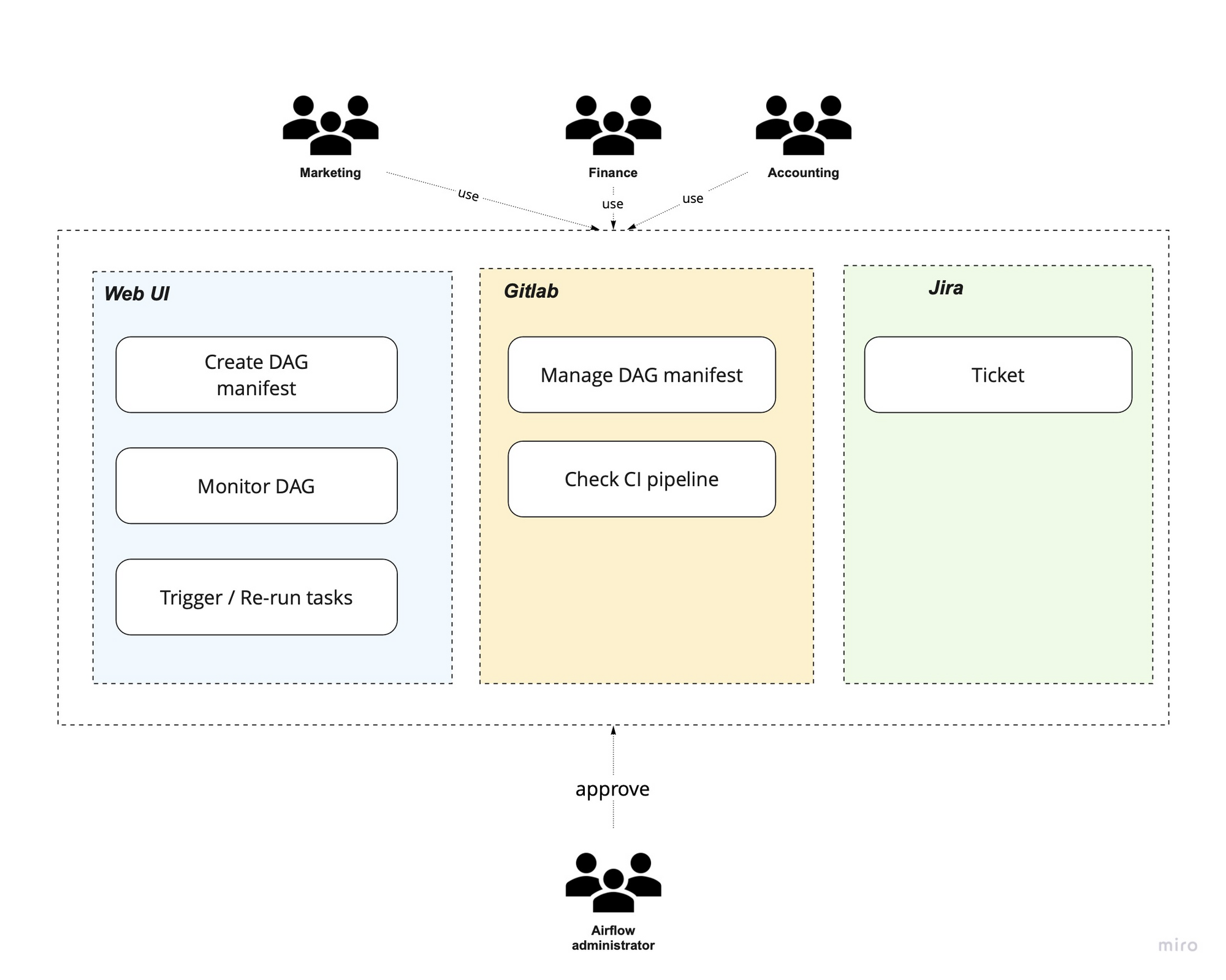
- Users can login to Airflow using their company account.
- Each user is assigned to different roles which are already linked to Airflow resources.
- The DAG belongs to its owners, it is the team or project that user is working on.
- Users can easily define the task in a configuration file (YAML, json) without any coding script.
- All defined DAG manifests are managed in Gitlab which helps us tracing all deployed tasks and versioning the task too. Each team also has their own repository in the Gitlab.
- Our CI/CD pipelines help user can test their DAG automatically before deploying to server.
- The secret/credentials are managed in Hashicorp Vault which is also linked to user role. We also provide the interface that user does not need to manage the secret by themselves but the security team instead. The only thing is they need is to declare the connection in their tasks. This interface helps the user to run the tasks related to PII data without touching them directly.
- For big data tasks (Spark, Hadoop, Hive,…) User can run those tasks in our bare metal big data server (not k8s environment where we deploy the Airflow), we called Hybrid deployment.
In technical view:
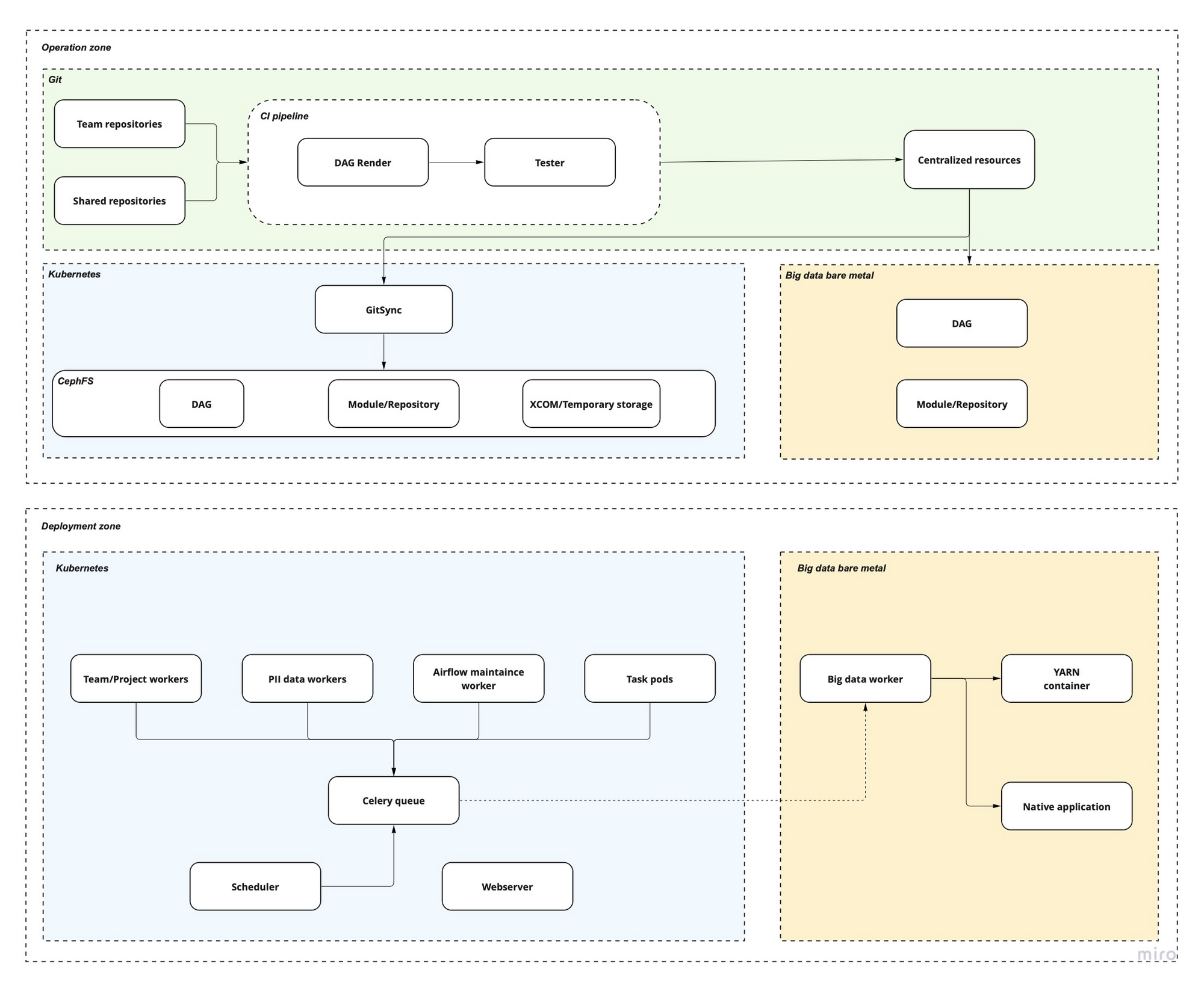
At the operation zone, we are using Gitlab as a place to store airflow deployment helm chart which helps us easily to manage the feature deployment across difference k8s environment. Our Helm chart is forked from Airflow official helm chart, but it is customized to integrate with our k8s deployment policy.
Airflow users also use Gitlab as a place to store their DAG manifest (a configuration files to define Airflow tasks instead of python script). For complex or specific tasks such as machine learning we also allow user can run their own managed operator which is also provided in a shared Gitlab repository. Those DAG repositories will be passed through CI pipeline to render to final python DAG and will be tested by our script before going to the centralized repo.
All successful DAG of all the team is stored in a centralized repo which are the same as Dag bag in Airflow. We use a sidecar tool called GitSync to synchronize the centralized repo to Airflow instance.
At our company, there are a lot of daily tasks that must be run in the bare metal big data server (Hadoop data). We also run Airflow worker in those machines to run the big data tasks that scheduled by Airflow scheduler.
We chose KubernetesCeleryExecutor as default executor which allows us able to split tasks into difference Celery queues:
- Normal tasks will be passed to a queue and taken by normal workers.
- PII data tasks will be taken by sensitive workers - a dedicated worker able to handle sensitive data tasks.
- Onprem - big data task will be taken by big data workers.
- Other dedicated workers will take specific tasks (airflow maintenance task or machine learning task).
This hybrid deployment allows our tasks to be run in different environments: in a Celery worker, a k8s pod or directly on a machine.
To deliver those features that allow us to run Airflow as a service, we customized them to integrate with our infrastructure:
- Dag render: an application to create Airflow tasks from manifest config files (YAML, json). More than that, we also developed a Web UI that can drag and drop the tasks instead of writing manifest file.
- LDAP and RBAC: We customized the authentication and authorization method to be able to synchronize the user roles from our company active directory automatically.
- Customized and managed operator: We disable some options to run the task and apply them automatically by our dag render policy.
- XCOM: We customize the XCOM to handle output of Airflow tasks that allow a task can share a large output to others.